Linux 文件系统
linux-filesystemLinux 文件系统中的文件是数据的集合,文件系统不仅包含着文件中的数据而且还有文件系统的结构,所有 Linux 用户和程序看到的文件、目录、软连接及文件保护信息等都存储在其中。
挂载
在 linux 操作系统中, 挂载是指将一个设备(通常是存储设备)挂接到一个已存在的目录上。 我们要访问存储设备中的文件,必须将文件所在的分区挂载到一个已存在的目录上, 然后通过访问这个目录来访问存储设备。
在安装 Linux 时,会让选择系统的安装位置。比如 “/” ,你要把他投放到哪块硬盘哪个分区下。当系统装完了后,你在 “/” 下读写文件,其实就是读写的那块物理硬盘的那个分区下的数据了。此时 “/” 被称作挂载点。
目录结构
Linux 中的目录结构是一个树状的,"/" 为最根节点,其下面的所有目录均是由 “/” 根目录所衍生出来的。
文件系统
Linux 中使用的最普遍的文件系统是 Extended filesystem。
当安装完 Linux 之后,那个安装的分区就被格式化成了这种文件系统。在这种文件系统里面,每个文件是使用 inode 与 block 来承载的。
inode 负责记录文件的属性,比如名称 大小 权限 之类的东西。还记录了 block 的号码。
block 则是负责记录文件的数据了。
当我要读取某一个文件的内容的时候,那么步骤应该是:
- 先从 inode 中取出文件权限,然后与你的权限对比,如果有权限进行下一步;
- 继而从 inode 中得到 block 号码,然后通过这个号码去找到对应的 block 读取数据。
再来详细说下 block。每个 block 的大小都是固定的,这个大小一般可以在格式化的时候指定的,比如这里拿 4K 来举例。我们说,文件数据是储存在 block 中的,但是此时我有一个 5K 的文件该怎么存?因为 block 的大小是 4K,而我们的数据要多出 1K 去,那这 1K 难道不要了?这时会再多分配出一个 4K 的 block 来存放那剩余的 1K 数据。(剩余 3K 浪费掉)
现在的情况是,一个 5K 的文件,使用 2 个 4K 的 block 来存储,虽然我们解决了存储 5K 文件的问题。但是这里就又有了一个新的问题。
在 inode 中记录的是 block 的号码,但是此时我们使用了 2 个 block 来存储的 5K 数据,那么在 inode 中记录的 block 号码,该记这 2 个 block 中的哪个呢?
当然是要全都记录下来,不然岂不是 5K 的文件在读取时只能得到 4K 。在 ext3 文件系统中,最多可以记录 12 个 block 号码,这里叫 直接块 。也就是最多可以存储 12 * 4K = 48K 。但是这也太少了吧?这意味着在 ext3 文件系统中每个块大小设置为 4K,单文件最大容量才 48K 呢。
所以在这时候,可以使用 一级间址 的形式来记录更大文件的 block 号码,首先先在 一级间址 中记录 一个 block 的号码,再由这一个 block 去记录整个文件的 block 的号码。因此 一级间址 形式最大存储文件大小是:
(4K / 4Byte) * 4K = 4M # 4Byte 是每个 block 号码占用的大小
但是这样能够储存的文件还是很小,所以就有了 二级间址、三级间址 ,和 一级间址 的原理是一样的,具体可以参考下面的这张图:
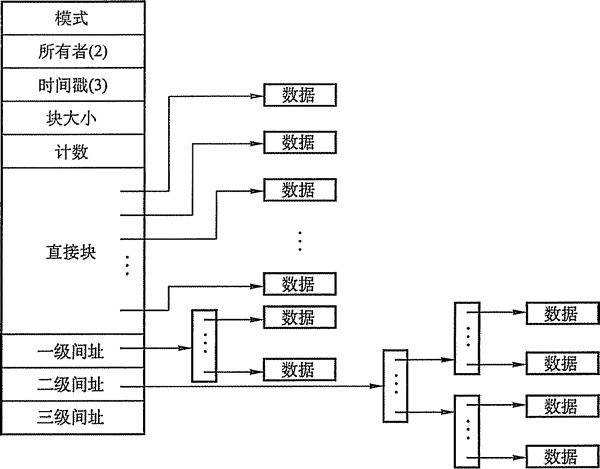
还是按照 4K 的 block 大小,来计算一下单个文件最大大小是多少:
12 * 4K # 直接块(48K)
+ (4K / 4Byte) * 4K # 一级间址(4M)
+ (4K / 4Byte) ^ 2 * 4K # 二级间址(4G)
+ (4K / 4Byte) ^ 3 * 4K # 三级间址(4T)
≈ 4T
虽然算出来的是 4T ,但是由于一些限制,实际达不到 4T。
在目前最新的 ext4 文件系统中,支持了使用 extent 树的形式存储数据块的映射结构,这意味着可以不再使用上面的 一级间址/二级间址/三级间址 这种繁琐且效率低下的方法了。
目录内容
现在已经知道了文件是如何存储的,但是目录又是怎么存储的呢?如何判定一个目录下面有哪些文件呢?
每个目录也对应于一个或多个 block ,而这个 block 就是记录文件名和文件的 inode 号码的关系对照表。例如下面这样:
| 文件名 | inode |
|---|---|
| a.mp4 | 100000 |
| b.mp4 | 100001 |
| …. | …. |
至于目录对应多少 block ,则是由目录文件数量决定的,如果文件多所分到的 block 数也就大。
现在我们应该能发现了,如果要读取 /a.mp4 ,那么要首先去读取 / 这个目录的 block (因为不读取的话你没法得到 a.mp4 这个文件的 inode 号码吧?)。等有了 inode 号码,再去根据 inode 对应的文件 block 读到文件内容。
所以,读取一个文件的步骤应该在前面再加上两条:
- 得到 / 的 inode (每个目录都有自己的 inode 号码,根目录的一般是
2); - 通过 / 的 inode 得到 / 的 block;
- 从 / 的 block 中得到文件的 inode 号;
- 从 inode 中取出文件权限,然后与你的权限对比,如果有权限进行下一步;
- 最后从 inode 中得到 block 号码,然后通过这个号码去找到对应的 block 读取数据。